If you're viewing this on your phone, I'd recommend enabling desktop mode. In Google Chrome, you can do so by tapping the three dots at the top right of your screen. Desktop Site usually has a checkbox next to it that you fill to enable the change. You can zoom in and out of any section with your fingers. My apologies for the hassle and thanks for reading!
Purpose¶
Here, I go through an exploratory analysis of Baltimore city employee salaries. I obtained all data through the City of Baltimore's Open Baltimore Data platform (OBD). I wanted to describe and illustrate a process for taking publicly available data and using it to conduct basic data analysis and visualization. All tools used here are free and open source (Google Cloud is a slight exception, but the free tier will get you pretty far).
Summary¶
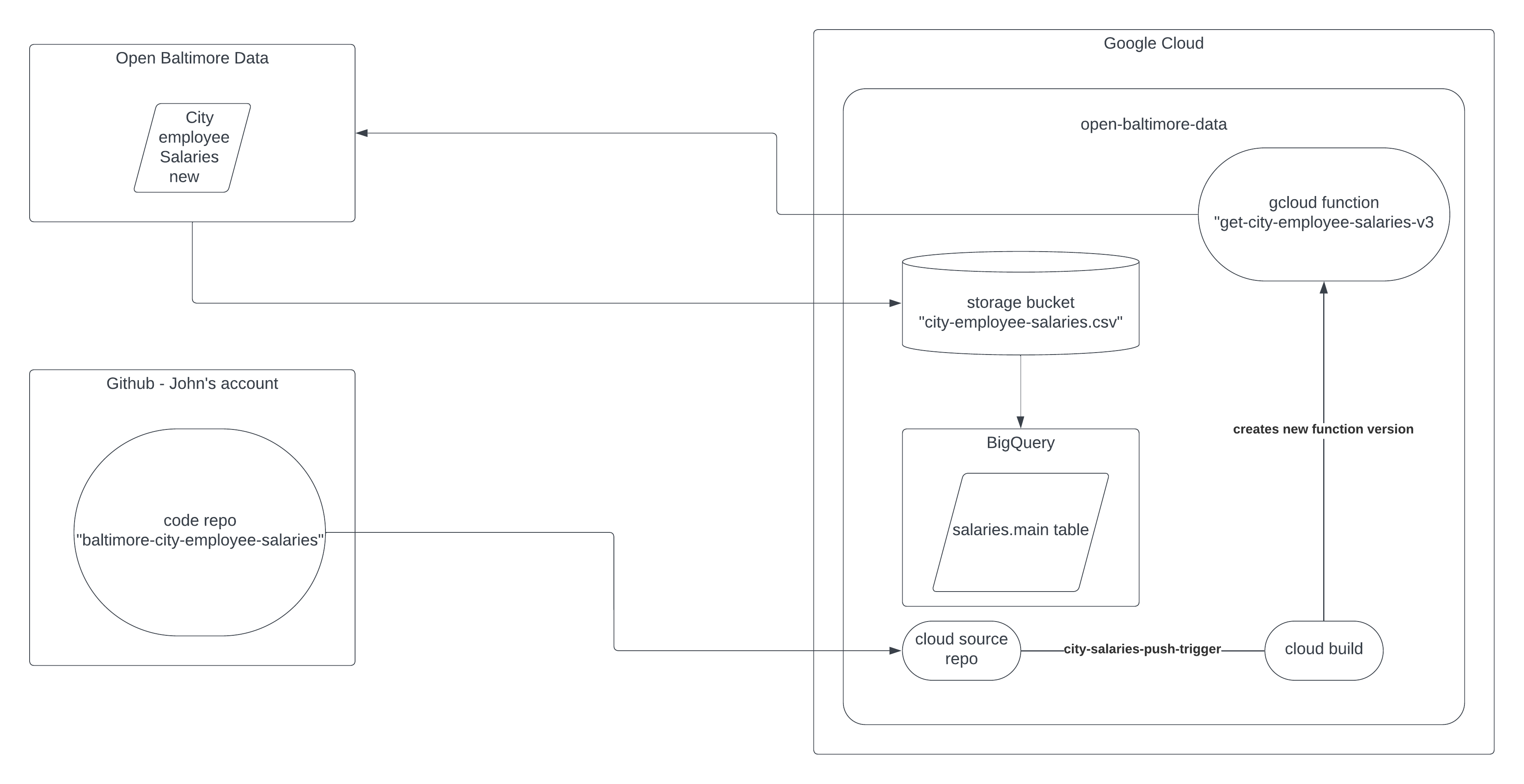
I created a small Python function that batches calls to the OBD Rest API. I connected the GitHub repo I stored the Python code in to a gcloud source repo. Each time I push a change to the master branch, GH notifies gcloud and Cloud Build uses the updated cloud source repo to deploy a new version to Cloud Function. Since OBD appears to only update the data once per year or so, I run the function manually. However, Cloud Scheduler would run my function at any interval I want using cronjobs.
Once the function finishes querying OBD, it stores the data in a csv in Cloud Storage. From there, I connect the csv to a BigQuery table. I considered updating the function to write directly to the BigQuery table, but I want to see how regularly OBD updates this data set going forward and if they change the schema. They've changed the schema for this dataset at least once that I've seen. I'll add some other details about this data set and a flow chart in the technical notes below.
Technical Notes and Disclosures¶
- OBD only has one name field, which made it difficult to group records by person for analysis. For example, I previously combined the
firstName,lastName, andmiddleInitialfields withAgencyIDto create anemployeeSlugthat I use to track workers across organizations. With just theNameandAgencyIDfields to work with in this release, tracking individual workers is difficult, though not impossible. It'll definitely be the work of a future analysis. This initial analysis focusses on agency-level salary measures. - I excluded salary records where the agency had less than 500 salary records total or the record omitted the
HireDatefield. I wanted to keep the initial anaylsis as robust as possible, so I elected to clean the data in this way. I also excluded records that were missing data in theannualSalaryfields since those fields were essential to my measures for this initial analysis. - I regrouped the raw
AgencyNamevalues because the data set duplicated some agency names, made distinctions inside of an agency I didn't want to keep, etc. For example, OBD broke out "Rec & Parks" to "Rec & Parks - Parks", "Rec & Parks - part-time", "Rec & Parks - Admin", etc.